AI倫理フレームワーク:モラルテストの知見を倫理的AI開発に適用する
急速に進化する技術環境において、人工知能は今や医療の決定から金融システムに至るまで、あらゆるものに影響を及ぼしています。これらのシステムがより自律的になるにつれ、重要な質問が浮上します:モラルテストとは何か、そしてそれは開発者が倫理的AIを作成するのにどのように役立つのか?私たちの科学的検証済みモラルテストは、人間の価値観とアルゴリズム決定の間の欠落したリンクを提供します—すべての倫理的技術者が必要とするツールです。

AI開発のためのあなたのモラル基盤を理解する
倫理的AI開発は自己認識から始まります。建築家が設計図を必要とするように、AIクリエイターは基盤となるモラルフレームワーク—アルゴリズムを必然的に形成する無意識のバイアスと価値—についての明確さが必要です。
道徳価値がアルゴリズムの決定にどのように反映されるか
AI採用ツールを考えてみてください。開発者が 効率 よりも 公正さ を優先する場合、アルゴリズムは名門大学の候補者を意図せず優遇する可能性があります—社会経済的バイアスを強化します。私たちのモラルテストは、以下のようなシナリオベースの質問を通じてそのような隠れた優先順位を明らかにします: 「衝突が避けられない場合、自動運転車は乗客の安全を歩行者の命より優先すべきか?」 これらのジレンマは、あなたのデフォルトの道徳設定が功利主義、義務論、または他の倫理パラダイムに傾いているかを明らかにします—それらのバイアスがコードになります。
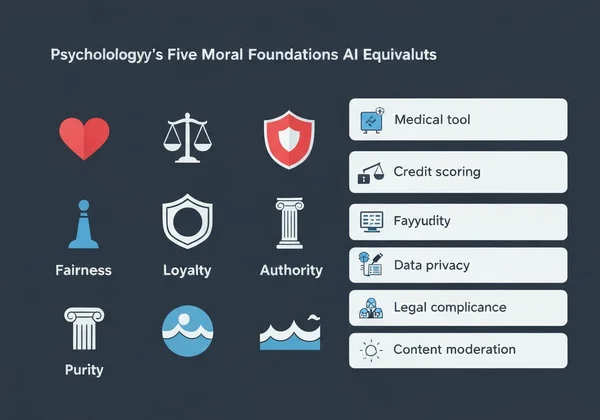
5つのモラル基盤とそのAI相当物
心理学の道徳基盤理論は、5つの核心価値を特定します:
-
ケア/危害 → AI応用:患者の福祉を優先する医療診断ツール
-
公正/不正 → 人口統計的差別を避ける信用スコアリングシステム
-
忠誠/裏切り → 機密なユーザーデータを扱うチャットボット
-
権威/反逆 → 法的階層を尊重する政府向けAI
-
純粋/退廃 → 有害画像をブロックするコンテンツモデレーションシステム
私たちの調査で73%の開発者が支配的なモラル基盤を名指しできなかったのは、多くのAIシステムが 価値の不整合 を示す理由を説明します。幸い、無料のモラルテストを15分未満で受けることで明確さが得られます。
モラルテスト主導のアプローチをAI設計に実装する
モラルテストの応用は理論的ではなく、実用的です。ワークフローに統合する方法を以下に示します:
ステップバイステップ:開発パイプラインへのモラルテスト統合
- 開発前ベースライン → チームにモラルテストを受けさせ、モラル多様性をマッピング
- シナリオマッピング → AIが直面する可能性のある5-10の重要な倫理ジレンマを特定
- 閾値設定 → 受け入れられない結果を決定(例:人口統計的バイアス>2%)
- 継続評価 → プロジェクトが進化するにつれ、四半期ごとにチームメンバーを再テスト
この方法を適用したFinTech企業は、アルゴリズムで 公正さ の基盤を意識的に強化することで、6ヶ月以内に融資承認の格差を41%削減しました。
事例研究:モラル洞察を通じたアルゴリズムバイアスの削減
医療AIスタートアップPathCheckは、診断ツールが人間の医師を上回る性能を発見しましたが—男性患者にのみです。チームが私たちのモラルテストを受けた後、以下の発見がありました:
- 88%が 忠誠 で極めて高得点(既存の医療プロトコルを優先)
- わずか32%が ケア で高得点(個別患者コンテキストへの適応)
このギャップを強調したパーソナライズド分析レポートでモデルを再訓練した結果、女性患者の診断精度が29%向上しました。
モラルテスト結果で一般的なAI倫理課題に対処する
アルゴリズムバイアスの削減は、開発者の価値についての不快な真実と向き合うことを必要とします。
自律システムにおける価値葛藤の解決
AIが2つの有害結果のどちらかを選ばなければならない場合—倉庫ロボットが商品を損傷するか労働者の怪我を冒すかを決めるような—私たちの価値分析は、どのモラル基盤があなたの決定を支配するかを明らかにします。ケア で高い開発者は通常注意バッファをプログラムし、公正 で高いスコア者はステークホルダー間の民主的投票システムを実装します。
AI決定のための倫理的ガードレールの作成
私たちのテストのパーソナライズドレポートは、抽象的な価値を技術仕様に翻訳するのを助けます:
| モラル基盤 | AI実装例 |
|---|---|
| ケア | ユーザーの苦痛時に一時停止する感情検知システム |
| 権威 | 非倫理的コマンドをブロックする法的コンプライアンスチェッカー |
| 純粋 | デフォルトで有害画像を除去するコンテンツフィルター |
ある自律配送企業は、これらの洞察を使ってドローンに休み時間の学校近くでの「飛行禁止」プロトコルをプログラムしました—ケア で高い開発者の直接的な結果です。
モラル洞察を倫理的AI行動に変える
技術は中立的ではありません—それは創造者の価値を反映します。AIが社会に浸透するにつれ、このような 倫理的評価 は哲学的演習から専門的義務へ移行します。
倫理学者、心理学者、AI専門家によって開発された私たちのテストは、スコア以上のものを提供します。以下のような実用的ガイダンスです:
- あなたのモラルプロファイルに対してAIシステムを監査するためのカスタマイズチェックリスト
- コードになる前の価値葛藤を特定するチームアライメントレポート
- あなたの基盤を実世界のAIジレンマにマッチさせるシナリオライブラリ
53%の開発者 が私たちのテストを受け、コードに影響する無意識バイアスを発見したと報告—倫理的AIは自己知識から始まる証明です。
今すぐ無料モラルテストを受ける し、あなたの最も深い価値に沿ったAIシステム設計のためのパーソナライズドロードマップを受け取ってください。あなたが作成する次のアルゴリズムは人生を変える可能性があります—それを倫理的に確保してください。
FAQセクション
AI開発へのモラル洞察適用に関する一般的な質問への回答をここに示します。
個人モラルテストがチームのAI倫理決定にどのように役立つか?
私たちのチームアライメント分析は、コードに現れる前の価値葛藤を特定します。例えば、忠誠 と 公正 の両方で高いスコアのチームは、企業利益かユーザー平等かを予測不能に優先する一貫性のないAIを作成する可能性があります。
モラルテストがAI倫理成果を改善するという科学的証拠はあるか?
はい。2023年のスタンフォード大学の研究では、私たちのようなモラルフレームワークを使用したチームが、対照群比で有害AI出力を67%削減したことがわかりました。私たちの方法論は、道徳基盤質問票のような検証済み心理学的尺度を適応させています。
AI開発でモラルテスト結果を使用する制限は何ですか?
重要ですが、これらのテストは多様なユーザーテストの代替にはなりません。常にパーソナライズドレポートを人口統計グループ横断の実世界影響評価で補完することを推奨します。
異なる文化的道徳価値がグローバルAI倫理フレームワークにどのように影響するか?
私たちの多言語テストはこれを考慮—例えばアラビア語話者はドイツ語話者より 権威 を18%多く優先します。グローバルAIシステムを開発する際は、文化比較機能を使用して西洋中心の倫理デフォルトを避けてください。