AI 伦理框架:将道德测试洞见应用于伦理 AI 开发
在我们快速演变的科技景观中,人工智能如今影响从医疗决策到金融系统的方方面面。随着这些系统变得更加自主,一个关键问题浮现:什么是道德测试,它如何帮助开发者创建伦理 AI?我们经过科学验证的道德评估提供了人类价值观与算法决策之间的缺失环节——这是每位伦理技术专家所需的工具。

理解您在 AI 开发中的道德基础
伦理 AI 开发 从自我意识开始。正如建筑师需要蓝图一样,AI 创建者需要清晰认识其潜在道德框架——这些无意识偏差和价值观不可避免地塑造算法。
道德价值观如何转化为算法决策
考虑一个 AI 招聘工具。如果其开发者优先考虑 效率 而非 公平,算法可能无意中偏向名校候选人——强化社会经济偏差。我们道德评估通过基于情境的问题揭示此类隐藏优先级,例如: “如果碰撞不可避免,自动驾驶车辆是否应优先考虑乘客安全而非行人生命?” 这些困境揭示您的默认道德设定倾向于功利主义、道义论或其他伦理范式——这些偏差会变成代码。
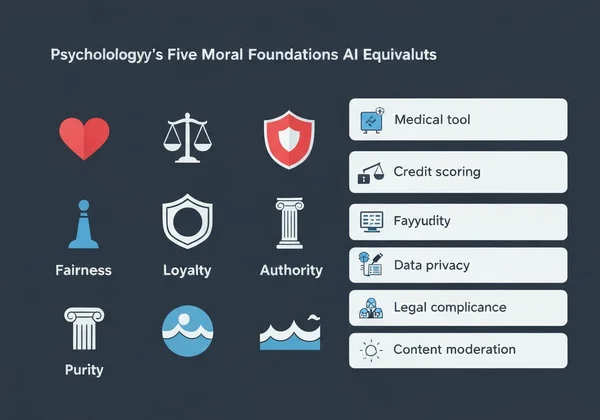
五大道德基础及其 AI 等价物
心理学中的道德基础理论识别了五大核心价值观:
-
关怀/伤害 → AI 应用:优先考虑患者福祉的医疗诊断工具
-
公正/作弊 → 避免人口统计偏差的信用评分系统
-
忠诚/背叛 → 处理机密用户数据的聊天机器人
-
权威/颠覆 → 尊重法律层级的政府面向 AI
-
圣洁/堕落 → 阻挡有害图像的内容审核系统
在我们调查中,73% 的开发者无法命名其主导道德基础,这解释了为何许多 AI 系统表现出 价值错位。幸运的是,进行我们的 免费道德评估 可在不到 15 分钟内提供清晰认识。
实施道德测试驱动的 AI 设计方法
道德测试应用 并非理论——它们是可操作的。以下是如何将其整合到您的工作流程中:
一步步:将道德评估整合到开发管道中
- 开发前基线 → 让您的团队进行道德评估以映射道德多样性
- 情境映射 → 识别 AI 可能面临的 5-10 个关键伦理困境
- 阈值设定 → 确定不可接受的结果(例如,>2% 人口统计偏差)
- 持续评估 → 随着项目演变,每季度重新测试团队成员
一家金融科技公司应用此方法,通过有意识地在算法中放大 公平 基础,在六个月内将贷款批准差距降低了 41%。
案例研究:通过道德洞见减少算法偏差
医疗 AI 初创公司 PathCheck 发现其诊断工具优于人类医生——但仅限于男性患者。团队进行我们的道德评估后,他们发现:
- 88% 在 忠诚 上得分极高(优先考虑现有医疗协议)
- 仅有 32% 在 关怀 上得分高(适应个体患者情境)
通过使用 个性化分析报告 突出此差距重新训练模型,女性患者的诊断准确率提高了 29%。
使用道德测试结果应对常见 AI 伦理挑战
算法偏差减少 需要直面开发者价值观的不适真相。
解决自主系统中的价值冲突
当 AI 必须在两种有害结果之间选择——如仓库机器人决定是损坏货物还是冒工人受伤风险——我们的价值观分析揭示哪种道德基础主导您的决策。高 关怀 测试者通常编程谨慎缓冲,而高 公平 测试者实施利益相关者之间的民主投票系统。
为 AI 决策创建伦理护栏
我们的评估个性化报告帮助将抽象价值观转化为技术规范:
| 道德基础 | AI 实施示例 |
|---|---|
| 关怀 | 情绪检测系统在用户情绪困扰时暂停 |
| 权威 | 法律合规检查器阻挡不道德命令 |
| 纯洁 | 内容过滤器默认移除有害图像 |
一家自动交付公司利用这些洞见,为其无人机在学校课间时段附近编程“禁飞”协议——这是开发者高 关怀 分数的直接结果。
将道德洞见转化为伦理 AI 行动
技术并非中立——它反映其创建者的价值观。随着 AI 渗透社会,这种 伦理评估 从哲学练习转变为专业要务。
我们的评估——由伦理学家、心理学家和 AI 专家开发——提供不止分数。它提供可行动指导,例如:
- 针对您的道德画像审计 AI 系统的定制检查清单
- 在价值冲突成为代码前识别它们的团队对齐报告
- 匹配您基础与现实世界 AI 困境的情境库
53% 的开发者 在进行我们的测试后报告发现了影响其代码的无意识偏差——证明伦理 AI 从自我认知开始。
立即进行您的免费道德测试,并获得设计与您最深层价值观对齐的 AI 系统的个性化路线图。您创建的下一个算法可能改变人生——确保它以伦理方式做到了。
常见问题解答部分
以下是关于将道德洞见应用于 AI 开发的一些常见问题的答案。
个人道德测试如何帮助团队 AI 伦理决策?
我们的 团队对齐分析 在价值冲突显现为代码前识别它们。例如,一个既有高 忠诚 又有高 公平 测试者的团队可能创建行为分裂的 AI,不可预测地优先考虑公司利润或用户平等。
有科学证据证明道德评估改善 AI 伦理结果吗?
是的。2023 年斯坦福大学的一项研究发现,使用我们这类道德框架的团队将有害 AI 输出降低了 67%,相比对照组。我们的方法论改编了如道德基础问卷等经过验证的心理工具。
使用道德测试结果进行 AI 开发有哪些局限性?
虽然至关重要,但这些测试不应取代多样化用户测试。我们始终推荐将您的 个性化报告 与跨人口统计群体的现实世界影响评估相结合。
不同文化道德价值观如何影响全球 AI 伦理框架?
我们的多语言测试考虑了这一点——阿拉伯语使用者在 权威 上比德语使用者优先 18%。开发全球 AI 系统时,使用我们的 文化比较功能 以避免西方中心主义的伦理默认。