AI 倫理框架:將道德測試洞見應用於倫理 AI 開發
在我們快速演變的科技環境中,人工智慧如今影響從醫療決策到金融系統的一切。隨著這些系統變得更具自主性,一個關鍵問題浮現:什麼是道德測試,以及它如何幫助開發者打造倫理 AI?我們科學驗證的道德測試提供了人類價值與演算法決策之間的缺失連結—每位倫理科技專家所需的工具。

理解您在 AI 開發中的道德基礎
倫理 AI 開發從自我覺察開始。正如建築師需要藍圖,AI 創造者需要釐清其底層道德框架—那些不可避免塑造演算法的無意識偏見與價值。
道德價值如何轉化為演算法決策
考慮一個 AI 徵才工具。如果其開發者將 效率 置於 公平 之上,演算法可能無意中偏好名校畢業生—強化社會經濟偏見。我們的道德測試透過情境式問題揭示此類隱藏優先事項,例如: "如果碰撞不可避免,自主駕駛車輛是否應優先乘客安全而非行人生命?" 這些兩難情境揭露您的預設道德設定傾向功利主義、義務論或其他倫理範式—這些偏見將成為程式碼。
五大道德基礎及其 AI 等價物
心理學的道德基礎理論辨識五項核心價值:
-
關懷/傷害 → AI 應用:優先患者福祉的醫療診斷工具
-
公平/作弊 → 避免人口統計歧視的信用評分系統
-
忠誠/背叛 → 處理機密使用者資料的聊天機器人
-
權威/顛覆 → 尊重法律階層的政府導向 AI
-
純潔/污染 → 阻擋有害影像的內容審核系統
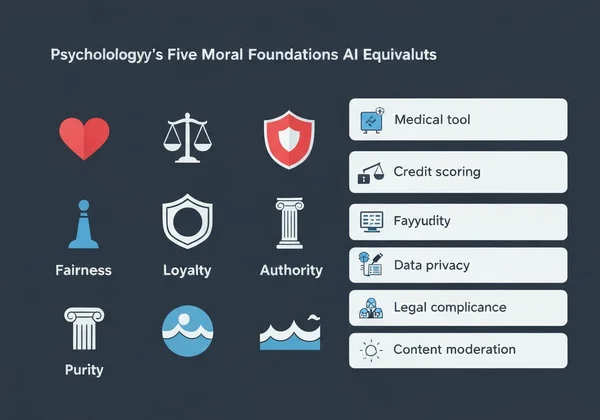
當我們調查顯示 73% 的開發者無法命名其主導道德基礎時,這解釋了為何許多 AI 系統展現 價值錯位。幸運的是,進行我們的 免費道德測試 即可在 15 分鐘內獲得清晰度。
實施道德測試導向的 AI 設計方法
道德測試應用並非理論—它們是可操作的。以下是如何將其整合至您工作流程:
逐步指南:將道德評估整合至開發管道
- 開發前基線 → 讓團隊進行道德測試以映射道德多樣性
- 情境映射 → 辨識 AI 可能面臨的 5-10 個關鍵倫理兩難
- 門檻設定 → 決定不可接受結果(例如 >2% 人口統計偏見)
- 持續評估 → 隨著專案演進,每季重新測試團隊成員
一家金融科技公司應用此方法,在六個月內透過有意識強化演算法中的 公平 基礎,將貸款核准差距降低 41%。
案例研究:透過道德洞見減少演算法偏見
醫療 AI 新創 PathCheck 發現其診斷工具優於人類醫師—但僅限男性患者。團隊進行我們的道德測試後,他們發現:
- 88% 在 忠誠 得分極高(優先既有醫療規範)
- 僅 32% 在 關懷 得分高(適應個別患者情境)
透過使用 個人化分析報告 突顯此差距重新訓練模型,女性患者的診斷準確率提升 29%。
以道德測試結果因應常見 AI 倫理挑戰
演算法偏見減少需要直面開發者價值的不適真相。
解決自主系統中的價值衝突
當 AI 必須在兩種有害結果間抉擇—例如倉儲機器人決定損壞貨物或冒險傷害工人—我們的價值分析揭示哪項道德基礎主導您的決策。高 關懷 測試者通常程式化警示緩衝,而高 公平 得分者則實施利益相關者民主投票系統。
為 AI 決策建立倫理護欄
我們的道德測試個人化報告幫助將抽象價值轉化為技術規格:
| 道德基礎 | AI 實施範例 |
|---|---|
| 關懷 | 使用者困擾時暫停的情緒偵測系統 |
| 權威 | 阻擋不倫理指令的法律合規檢查器 |
| 純潔 | 預設移除有害影像的內容過濾器 |
一家自主配送公司在學校課間休息時間附近,為其無人機設定「禁飛」協議—這是開發者 關懷 得分高的直接結果。
將道德洞見轉化為倫理 AI 行動
科技並非中立—它反映創造者的價值。隨著 AI 滲透社會,此類 倫理評估從哲學練習轉變為專業要務。
我們的道德測試—由倫理學家、心理學家與 AI 專家開發—提供不僅是分數。它提供可行動指導,例如:
- 依您的道德輪廓審核 AI 系統的自訂檢查清單
- 辨識價值衝突轉為程式碼前之團隊對齊報告
- 匹配您基礎與真實世界 AI 兩難的情境庫
53% 的開發者進行我們的測試後報告發現影響程式碼的無意識偏見—證明倫理 AI 從自我認知開始。
立即進行您的免費道德測試,並獲得個人化路線圖,用於設計與您最深價值對齊的 AI 系統。您即將創造的下一個演算法可能改變人生—確保它以倫理方式達成。
常見問題專區
以下是關於將道德洞見應用於 AI 開發的一些常見問題解答。
個人道德測試如何幫助團隊 AI 倫理決策?
我們的 團隊對齊分析 在價值衝突顯現為程式碼前辨識它們。例如,一個同時擁有高 忠誠 與高 公平 得分者的團隊,可能創造出精神分裂的 AI,難以預測地優先公司利潤或使用者平等。
道德測試改善 AI 倫理成果是否有科學證據?
有。2023 年史丹佛研究發現,使用如我們道德框架的團隊,相較對照組將有害 AI 輸出減少 67%。我們的方法論改編自經驗證的心理工具,如道德基礎問卷。
使用道德測試結果於 AI 開發的限制為何?
雖然關鍵,這些測試不應取代多樣使用者測試。我們始終建議以橫跨人口群體的真實世界影響評估,補充您的 個人化報告。
不同文化道德價值如何影響全球 AI 倫理框架?
我們的多元語言測試考量此點—例如,阿拉伯語使用者比德語使用者優先 權威 多 18%。開發全球 AI 系統時,使用我們的 文化比較功能 以避免西方中心倫理預設。